Introduction
In this post, we'll load a large GeoJSON file into MongoDB by ijson (a Python package). Then we'll answer two questions using MongoDB aggregation pipelines; SQL queries are also given for comparisions. We'll wrap up with visualizing querying results on a map.
How large is large?
A file large for a computer may be nothing for another powerful one. By 'large', we're not talking about big data stored and distributed across clusters of hundreds of servers operating in parallel, but files that can't be handled easily by our laptops or a single server.
JSON
JSON is a popular lightweight data interchange format for internet of things. Unlike CSV files whose structures can be easily inferred from the header or a few lines, JSON files have flexible schemas which are good for storing and retriving unstructred data, but not easy to be read in chucks.
A JSON file is probably large for a computer if:
- The cursor of the text editor such as Vim or Emacs gets bogged down in the file.
- The computer becomes slow with frequent not responding when reading the file using Python
json.load()orpandas.read_json()because its size is too much for the memory.
Now we have a 1.1 GB US Zip3 GeoJSON file, and suppose it's large for our computers. Let's figure out how to wrangle it.
Take a look at the data
Linux command line comes in handy when we want to get a feel for our data.
$ less uszip3.json
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"geometry": {
"type": "Polygon",
"coordinates": [
[
[
-118.30289799964294,
34.15840300009842
],
$ tail -12 uszip3.json
"properties": {
"ZIP3": "999",
"POP13_SQMI": "7.20000000000e-001",
"Shape_Area": "2.79540779104e+000",
"Shape_Leng": "7.63101677519e+001",
"POP2013": 5425,
"STATE": "AK",
"SQMI": "7.58330000000e+003"
}
}
]
}
Profile time and memory usage
We're trying to read the JSON file using pandas and ijson. To make comparisons quantitatively, we harness a decorator to measure time and memory consumed by functions.
import time
import inspect
from functools import wraps
from memory_profiler import memory_usage
from functools import partial
measure_memory = partial(memory_usage, proc=-1, interval=0.2, timeout=1)
def measure_usage(func):
"""A decorator to profile the usage of time and memory by a function"""
@wraps(func)
def wrapper(*args, **kwargs):
print("Before function <{}>, memory usage: {:.2f} MiB"
.format(func.__name__, measure_memory()[0]))
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print("After function <{}> done, memory usage: {:.2f} MiB"
.format(func.__name__, measure_memory()[0]))
print("Function <{}> took {:.2f} s".format(func.__name__, end - start))
return result
return wrapper
Load the file using pandas.
INFILE = 'uszip3.json' # the large GeoJSON file
import pandas as pd
@measure_usage
def read_by_pandas(infile):
df = pd.read_json(infile)
print("In function <{}>, memory usage: {:0.1f} MiB"
.format(inspect.stack()[0][3], measure_memory()[0]))
read_by_pandas(INFILE)
We also load the file using ijson, which will be talked about soon. To make comparisions between the two packages, the measuring results are listed here.
| <read_by_pandas> | <ijson_to_mongodb>
-----------------------------------|------------------|---------------------
Before function, memory usage: | 73.86 MiB | 40.00 MiB
In function, memory usage: | 1916.3 MiB | 60.61 MiB
After function done, memory usage: | 71.19 MiB | 60.62 MiB
Function took | 89.61 s | 1065.59 s
From the table, we can see the huge differences between pandas.read_json() and ijson:
- pandas uses about 1.9 GB memory just loading the file to DataFrame. I could barely do anything else on my computer during the reading. If I would try to parse the JSON file, chances are my computer won't respond any more and I have to restart it.
- The function
ijson_to_mongodbnot only reads the file but parse it and insert data into MongoDB. It took about 18 minutes, but the memory usage was only about 60 MB. At the same time I did other things normally on my computer.
Python standard library json has the same issue as pandas.read_json(), so we need other packages to handle the large JSON file.
Read the file in a lazy way
Python iterator is an object representing a stream of data. It doesn't read the whole thing into memory, but returns its members one at a time. ijson is an iterative JSON parser - a Python package we'll use.
First let's get the schema of the JSON file using ijson.
import ijson
with open(INFILE, 'r') as f:
objects = ijson.items(f, 'features.item')
for ob in objects:
print('Top level keys: {}'.format(list(ob.keys())))
print("'geometry' has keys: {}\n"
"'properties' has keys: {}"
.format(list(ob['geometry'].keys()),
list(ob['properties'].keys())))
break
Top level keys: ['geometry', 'properties', 'type']
'geometry' has keys: ['type', 'coordinates']
'properties' has keys: ['Shape_Area', 'SQMI', 'Shape_Leng', 'POP2013', 'ZIP3', 'STATE', 'POP13_SQMI']
Load the JSON file into MongoDB
The reason we load the JSON file into MongoDB
Ijson is good but slow. It's unacceptable to always wait for minutes every time we explore the file. That's the case MongoDB excels in -- the powerful MongoDB engine lets us explore the data fast and easily.
MongoDB provides a tool mongoimport which is good for importing line-delimited JSON files, and content export created by another tool mongoexport. However, the tool often gave me a headache when importing JSON files created by other third-party export tools. This US Zip3 GeoJSON was no exception.
A better way is to use PyMongo, a driver working with MongoDB from Python. Let's look at the code.
import simplejson as json
import pymongo
DEBUG = False # set DEBUG to False for production
INDENT_NUM = 2 if DEBUG else None # for json pretty printing
json_dumps = partial(json.dumps, indent=INDENT_NUM)
@measure_usage
def ijson_to_mongodb(infile, collection):
"""Read a JSON file lazily, then insert data into MongoDB"""
with open(infile, 'r') as f:
objects = ijson.items(f, 'features.item')
cnt = 0
for ob in objects:
result = collection.insert_one(json.loads(json_dumps(ob)))
print("In function <{}>, memory usage: {:0.2f} MiB"
.format(inspect.stack()[0][3], measure_memory()[0]))
return result
if __name__ == '__main__':
try:
client = pymongo.MongoClient('localhost', 27017)
db = client.datalab # the MongoDB database we use
collection = db.uszip3 # collection in the database
collection.find_one({}) # quick test the database
except pymongo.errors.PyMongoError as e:
print('**MongoDB Error**', e)
else:
ijson_to_mongodb(INFILE, collection) # it took about 18 minutes
Note:
I use import simplejson as json instead of Python standard library json because the latter doesn't deal with decimal numbers in latitude and longitude. To avoid TypeError, you have to define a helper function for the default parameter of json.dumps(). Fortunately, simplejson.dumps() serializes decimal numbers to JSON with full precision. See here for details.
Ask databases
Now that we have the JSON data in MongoDB, let's ask two simple questions, and answer them by both MongoDB aggregation pipelines and SQL (PostgreSQL) queries. (I've imported the data except for the geometry information into PostgreSQL.)
Questio 1: What are the top three states in terms of the number of zip3 codes in each state?
MongoDB solution:
def rank_state_by_number_of_zip3(collection, N):
"""Return a cursor representing top N state
in terms of the number of zip3 codes"""
pipeline = [
{'$match': {'properties.POP2013': {'$gt': 0}}},
{'$project': {'_id': 0, 'properties': 1}},
{'$group': {'_id': '$properties.STATE',
'count': {'$sum': 1}}},
{'$sort': {'count': -1}},
{'$limit': N}
]
result = collection.aggregate(pipeline)
return result
{'_id': 'CA', 'count': 57}
{'_id': 'NY', 'count': 50}
{'_id': 'TX', 'count': 47}
SQL solution:
-- The top 3 states in terms of the number of zip3 codes in each state
SELECT state, count(zip3) AS cnt_zip3
FROM uszip3
WHERE pop2013 > 0
GROUP BY state
ORDER BY cnt_zip3 DESC
LIMIT 3;
state | cnt_zip3
-------+----------
CA | 57
NY | 50
TX | 47
Questio 2: What are the top three zip3 codes by population in North Carolina (NC) and Virgina (VA)?
MongoDB solution:
def rank_zip3_by_pop_each_state(collection, N, state):
"""Return a cursor representing top N zip3 by population in the state"""
assert isinstance(state, str), 'state should be a string'
pipeline = [
{"$match": {"properties.STATE": {"$eq": state}}},
{"$project": {"_id": 0,
"properties.ZIP3": 1,
"properties.POP2013": 1,
"properties.STATE": 1}},
{"$sort": {"properties.POP2013": -1}},
{"$limit": N}
]
result = collection.aggregate(pipeline)
return result
if __name__ == '__main__':
# ... same code as above
else:
N = 3
for state in ('NC', 'VA'):
result = rank_zip3_by_pop_each_state(collection, N, state)
for res in result:
print(res)
{'properties': {'POP2013': 1111755, 'STATE': 'NC', 'ZIP3': '275'}}
{'properties': {'POP2013': 857761, 'STATE': 'NC', 'ZIP3': '283'}}
{'properties': {'POP2013': 819280, 'STATE': 'NC', 'ZIP3': '282'}}
{'properties': {'POP2013': 886499, 'STATE': 'VA', 'ZIP3': '201'}}
{'properties': {'POP2013': 573094, 'STATE': 'VA', 'ZIP3': '234'}}
{'properties': {'POP2013': 547384, 'STATE': 'VA', 'ZIP3': '232'}}
SQL solution:
-- The top 3 zip3 by population in North Carolina (NC) and Virgina (VA)
SELECT state, zip3, pop2013
FROM (SELECT zip3, pop2013, state,
rank() OVER (PARTITION BY state ORDER BY pop2013 DESC) AS pos
FROM uszip3
WHERE state IN ('NC', 'VA') AND pop2013 > 0
) t
WHERE pos <= 3;
state | zip3 | pop2013
-------+-------+---------
NC | 275 | 1111755
NC | 283 | 857761
NC | 282 | 819280
VA | 201 | 886499
VA | 234 | 573094
VA | 232 | 547384
The output from both databases is same. In PostgreSQL, it's convinent to use the window function RANK() to get the results. In MongoDB I had to iterate over each state. Are there similar window functions in MongoDB?
Retrieving and visualizing documents
With a GeoJSON file, it's natural to look at the data on a map. We extract top 10 zip3 by population in Washington state, and use Leaflet to create a choropleth map.
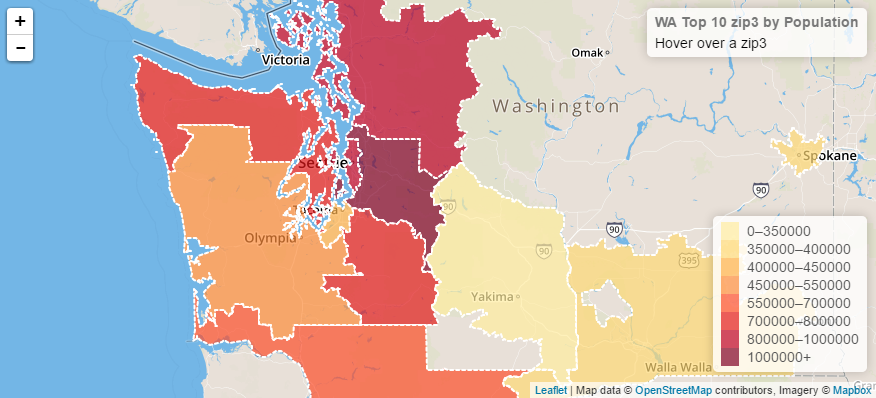
Summary
We have used an iterative JSON parser ijson to load a large GeoJSON file into databases. Then we test them by asking two simple questions, extracting a subset of the data, and visualizing it on a map. Here are further ideas:
- It's possible to reduce the size of an indented JSON file by removing the leading spaces.
trsqueeze orsedreplace can do it, but you should know what you do to guarantee no information is lost. - Both relational databases and NoSQL document databases are powerful but for different applications. They are not good at everything. Technology changes fast, so in the near future PostgreSQL might support horizontal scaling well, and MongoDB might support complex transactions and more powerful analytic capabilities.
Thanks for reading!